Что такое ветка?
Чтобы на самом деле разобраться в том, как Git работает с ветками, мы должны сделать шаг назад и рассмотреть, как Git хранит свои данные. Как вы, наверное, помните из главы 1, Git хранит данные не как последовательность изменений или дельт, а как последовательность снимков состояния (snapshot).
Когда вы создаёте коммит в Git'е, Git записывает в базу объект-коммит, который содержит указатель на снимок состояния, записанный ранее в индекс, метаданные автора и комментария и ноль и более указателей на коммиты, являющиеся прямыми предками этого коммита: ноль предков для первого коммита, один — для обычного коммита и несколько — для коммита, полученного в результате слияния двух или более веток.
Для наглядности давайте предположим, что у вас есть каталог, содержащий три файла, и вы хотите добавить их все в индекс и сделать коммит. При добавлении файлов в индекс для каждого из них вычислится контрольная сумма (SHA-1 хеш, о котором мы упоминали в главе 1), затем эти версии файлов будут сохранены в Git-репозиторий (Git обращается к ним как к двоичным данным), а их контрольные суммы добавятся в индекс:
$ git add README test.rb LICENSE
$ git commit -m 'initial commit of my project'
Когда вы создаёте коммит, выполняя git commit, Git
вычисляет контрольную сумму каждого подкаталога (в нашем случае только
корневого каталога) и сохраняет эти объекты-деревья в Git-репозиторий.
Затем Git создаёт объект для коммита, в котором есть метаданные и
указатель на объект-дерево для корня проекта. Таким образом, Git сможет
воссоздать текущее состояние, когда будет нужно.
Ваш Git-репозиторий теперь содержит пять объектов: по одному блобу для содержимого каждого из трёх файлов, одно дерево, в котором перечислено содержимое каталога и определено соответствие имён файлов и блобов, и один коммит с указателем на тот самый объект-дерево для корня и со всеми метаданными коммита. Схематично данные в этом Git-репозитории выглядят так, как показано на рисунке 3-1.
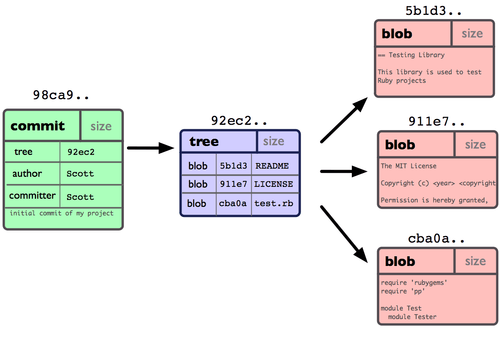
Рисунок 3-1. Данные репозитория с единственным коммитом.
Если вы сделаете некоторые изменения и создадите новый коммит, то следующий коммит сохранит указатель на коммит, который шёл непосредственно перед ним. После следующих двух коммитов история может выглядеть, как на рисунке 3-2.
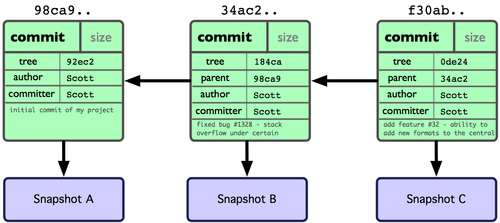
Рисунок 3-2. Данные объектов Git'а для нескольких коммитов.
Ветка в Git'е — это просто легковесный подвижный указатель на один из этих коммитов. Ветка по умолчанию в Git'е называется master. Когда вы создаёте коммиты на начальном этапе, вам дана ветка master, указывающая на последний сделанный коммит. При каждом новом коммите она сдвигается вперёд автоматически.
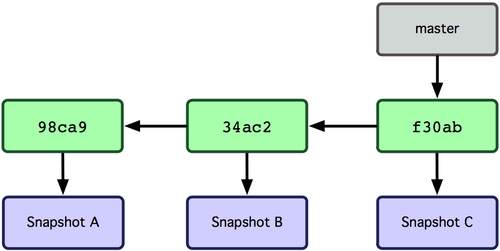
Рисунок 3-3. Ветка указывает на историю коммитов.
Что произойдёт, если вы создадите новую ветку? Итак, этим вы
создадите новый указатель, который можно будет перемещать. Скажем,
создадим новую ветку под названием testing. Это делается командой git branch:
$ git branch testing
Эта команда создаст новый указатель на тот самый коммит, на котором вы сейчас находитесь (см. рис. 3-4).
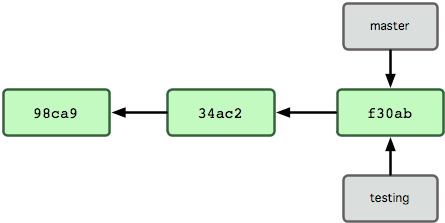
Рисунок 3-4. Несколько веток, указывающих на историю коммитов.
Откуда Git узнает, на какой ветке вы находитесь в данный момент? Он
хранит специальный указатель, который называется HEAD (верхушка).
Учтите, что это сильно отличается от концепции HEAD в других СКВ, таких
как Subversion или CVS, к которым вы, возможно, привыкли. В Git'е это
указатель на локальную ветку, на которой вы находитесь. В данный момент
вы всё ещё на ветке master. Команда git branch только создала новую ветку, она не переключила вас на неё (см. рис. 3-5).
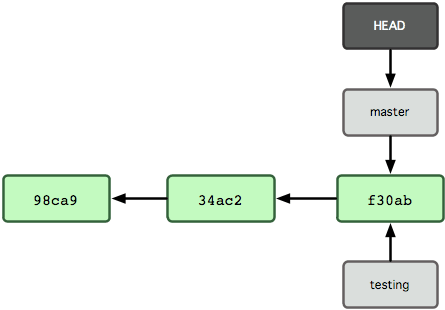
Рисунок 3-5. Файл HEAD указывает на текущую ветку.
Чтобы перейти на существующую ветку, вам надо выполнить команду git checkout. Давайте перейдём на новую ветку testing:
$ git checkout testing
Это действие передвинет HEAD так, чтобы тот указывал на ветку testing (см. рис. 3-6).
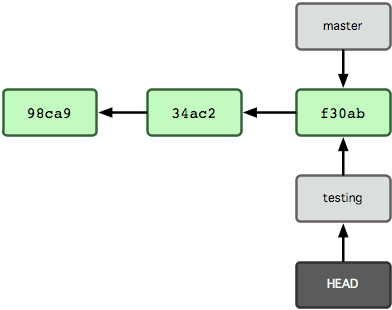
Рисунок 3-6. HEAD указывает на другую ветку после переключения веток.
В чём же важность этого? Давайте сделаем ещё один коммит:
$ vim test.rb
$ git commit -a -m 'made a change'
На рисунке 3-7 показан результат.
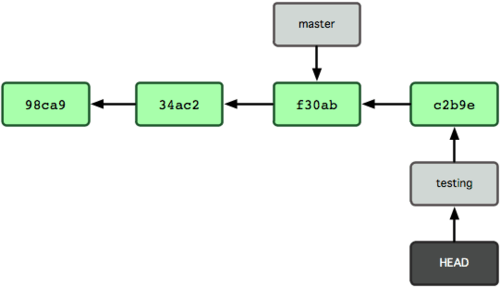
Рисунок 3-7. Ветка, на которую указывает HEAD, движется вперёд с каждым коммитом.
Это интересно, потому что теперь ваша ветка testing передвинулась вперёд, но ветка master всё ещё указывает на коммит, на котором вы были, когда выполняли git checkout, чтобы переключить ветки. Давайте перейдём обратно на ветку master:
$ git checkout master
На рисунке 3-8 можно увидеть результат.
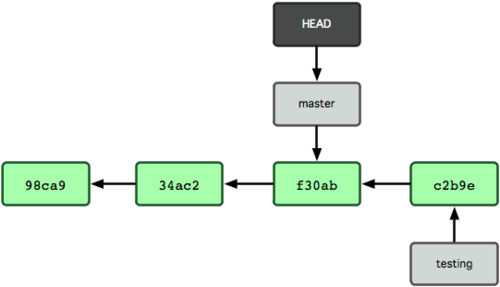
Рисунок 3-8. HEAD перемещается на другую ветку при checkout'е.
Эта команда выполнила два действия. Она передвинула указатель HEAD назад на ветку master и вернула файлы в вашем рабочем каталоге назад, в соответствие со снимком состояния, на который указывает master.
Это также означает, что изменения, которые вы делаете, начиная с этого
момента, будут ответвляться от старой версии проекта. Это, по сути,
откатывает изменения, которые вы временно делали на ветке testing, так что дальше вы можете двигаться в другом направлении.
Давайте снова внесём немного изменений и сделаем коммит:
$ vim test.rb
$ git commit -a -m 'made other changes'
Теперь история вашего проекта разветвилась (см. рис. 3-9). Вы создали
новую ветку, перешли на неё, поработали на ней немного, переключились
обратно на основную ветку и выполнили другую работу. Оба эти изменения
изолированы в отдельных ветках: вы можете переключаться туда и обратно
между ветками и слить их, когда будете готовы. И всё это было сделано
простыми командами branch и checkout.
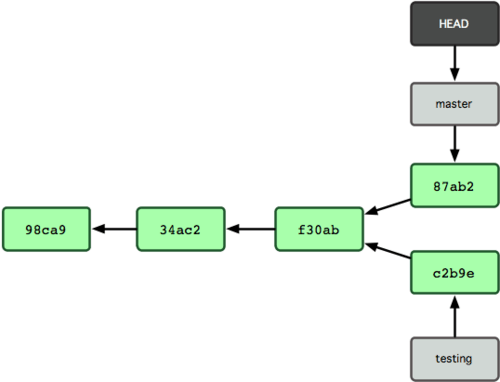
Рисунок 3-9. История с разошедшимися ветками.
Из-за того, что ветка в Git'е на самом деле является простым файлом, который содержит 40 символов контрольной суммы SHA-1 коммита, на который он указывает, создание и удаление веток практически беззатратно. Создание новой ветки настолько же быстрое и простое, как запись 41 байта в файл (40 символов + символ новой строки).
Это разительно отличается от того, как в большинстве СКВ делается ветвление. Там это приводит к копированию всех файлов проекта в другой каталог. Это может занять несколько секунд или даже минут, в зависимости от размера проекта, тогда как в Git'е это всегда происходит моментально. Также благодаря тому, что мы запоминаем предков для каждого коммита, поиск нужной базовой версии для слияния уже автоматически выполнен за нас, и в общем случае слияние делается легко. Эти особенности помогают поощрять разработчиков к частому созданию и использованию веток.
Давайте поймём, почему и вам стоит так делать.
prev | next